Recently a customer called us that there is something wrong after upgrading Oracle Database to 19.15 on RedHat. Apparently The amount of RAM consumed by DBWR and process servers became really impressive – as a proof I got screenshots looking like this:
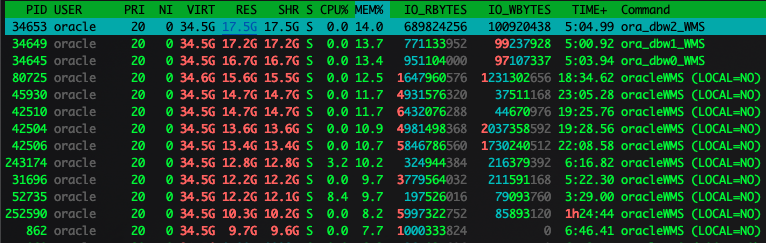
They said that before the migration it never looked like this and asked for explanation, so Radek Kut and I started to investigate the mysterious case of memory leak in Oracle 19.15. 😉
Before you go any further with this post, please get familiar with this document by Frits Hoogland:
https://fritshoogland.files.wordpress.com/2018/02/linux-memory-explained.pdf
Ok, now that you know what is going on with memory on Linux level and you understand what RSS memory is, let’s look at the screenshot once again – a column RES, actually means RSS. So it looks like that database writer processes are using more than 17G of RAM, but before migration they used not more than 200M!
Funny isn’t it?
If you read Frits’s article carefully you probable understand by now that RSS is not a statistic that actually tells us how much memory is consumed by a process and you correctly suspect that there is something wrong with those numbers.
After some investigation it has occurred that only one thing changed during an upgrade – previously the whole SGA was allocated in huge pages and now the database is using regular ones.
Let’s try to understand the difference.
First of all I want to be sure that my Oracle instance won’t be using large pages at all:
SQL> alter system
2 set use_large_pages=FALSE
3 scope=spfile;
System altered.
SQL> startup force
ORACLE instance started.
Total System Global Area 2147482384 bytes
Fixed Size 9136912 bytes
Variable Size 838860800 bytes
Database Buffers 1291845632 bytes
Redo Buffers 7639040 bytes
Database mounted.
Database opened.
SQL>
Let’s start a new session:
SQL> show con_name
CON_NAME
------------------------------
ORCLPDB1
SQL> show user
USER is "HR"
Now I will check SPID of my process server:
SQL> select spid
2 from v$process p, v$session s
3 where p.addr = s.paddr
4 and s.username='HR';
SPID
------------------------
75149
SQL>
When we have SPID, we can check the RSS counters, related to Oracle shared memory allocated in operating system for SGA:
[oracle@dbVictim ~]$ cat /proc/75149/smaps | grep SYSV000 -A 10 | grep Rss
Rss: 0 kB
Rss: 488 kB
Rss: 17280 kB
Rss: 12 kB
Great, keep that in mind and run a query on some "big" table in our HR session:
SQL> select count(distinct dbms_rowid.rowid_block_number(rowid)) as cnt
2 from hr.employees2;
CNT
----------
35839
35 839 blocks is ~ 280MB. Now let’s compare RSS counters for our process:
[oracle@dbVictim ~]$ cat /proc/75149/smaps | grep SYSV000 -A 10 | grep Rss
Rss: 0 kB
Rss: 516 kB
Rss: 336624 kB
Rss: 12 kB
Awesome! So Reading from buffer cache is accumulated in RSS statistics! But what if I turn on huge pages?
SQL> alter system
2 set use_large_pages=only
3 scope=spfile;
System altered.
SQL> startup force
ORACLE instance started.
Total System Global Area 2147482384 bytes
Fixed Size 9136912 bytes
Variable Size 838860800 bytes
Database Buffers 1291845632 bytes
Redo Buffers 7639040 bytes
Database mounted.
Database opened.
What would be shown in my Rss counters for session that issues the above SQL on EMPLOYEES2?
[oracle@dbVictim ~]$ cat /proc/75666/smaps | grep SYSV000 -A 10 | grep Rss
Rss: 0 kB
Rss: 0 kB
Rss: 0 kB
Nothing, nada, nic!
The same for DBWR on any other Oracle RDBMS process!
[oracle@dbVictim ~]$ cat /proc/`pidof ora_dbw0_ORCLCDB`/smaps | grep SYSV000 -A 10 | grep Rss
Rss: 0 kB
Rss: 0 kB
Rss: 0 kB
And this is not an Oracle-related "problem". Look at this simple code in C that can simulate the similar situation:
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <wait.h>
#include <string.h>
#include <sys/stat.h>
#include <sys/shm.h>
enum {SEGMENT_SIZE = 0xA00000};
const char *data = "dupa";
int main(int argc, char *argv[]) {
int status;
int segment_id;
int huge_small;
printf("Hugepages (1) or regular pages (2): ");
scanf("%d", &huge_small);
if(huge_small == 1) {
segment_id = shmget (0x42b33125, SEGMENT_SIZE,
IPC_CREAT | S_IRUSR | S_IWUSR | SHM_HUGETLB);
}
else {
segment_id = shmget (0x42b33125, SEGMENT_SIZE,
IPC_CREAT | S_IRUSR | S_IWUSR);
}
char *sh_mem = (char *) shmat(segment_id, NULL, 0);
printf("Segment ID %d\n", segment_id);
printf("Attached at %p\n\n\n", sh_mem);
int write_read;
while(1) {
printf("Want to write (1), read (2) or exit (0): ");
scanf("%d", &write_read);
if(write_read == 1) {
int kb;
printf("How many kb to write: ");
scanf("%d", &kb);
for(int i = 0; i < kb*256; i++) {
memmove(sh_mem+strlen(sh_mem), data, strlen(data)+1);
}
} else if (write_read == 2) {
printf("Read %d bytes\n", strlen(sh_mem));
} else if (write_read == 0) {
break;
}
}
shmdt(sh_mem);
shmctl(segment_id, IPC_RMID, 0);
exit(EXIT_SUCCESS);
}
Let’s see what will happen when we use it with regular – small pages:
In the first session I will write 10kb into shared memory:
[root@dbVictim ~]# ./shared_memory
Hugepages (1) or regular pages (2): 2
Segment ID 48
Attached at 0x7fb6585df000
Want to write (1), read (2) or exit (0): 1
How many kb to write: 10
Want to write (1), read (2) or exit (0):
In the second one I will ask my program to read it:
[root@dbVictim ~]# ./shared_memory
Hugepages (1) or regular pages (2): 2
Segment ID 48
Attached at 0x7f33c0b5f000
Want to write (1), read (2) or exit (0): 2
Read 10240 bytes
Want to write (1), read (2) or exit (0):
And those are the Rss counters for my second program which read the data from a shared memory segment:
[root@dbVictim ~]# cat /proc/`pidof -s shared_memory`/smaps | grep 42b33125 -A 22 | grep Rss
Rss: 12 kB
Great, let’s increase to 100kb:
[root@dbVictim ~]# ./shared_memory
Hugepages (1) or regular pages (2): 2
Segment ID 50
Attached at 0x7efd3aabd000
Want to write (1), read (2) or exit (0): 1
How many kb to write: 100
And read it:
[root@dbVictim ~]# ./shared_memory
Hugepages (1) or regular pages (2): 2
Segment ID 50
Attached at 0x7f520f835000
Want to write (1), read (2) or exit (0): 2
Read 102400 bytes
Want to write (1), read (2) or exit (0):
What do counters say?
[root@dbVictim ~]# cat /proc/`pidof -s shared_memory`/smaps | grep 42b33125 -A 22 | grep Rss
Rss: 104 kB
Awesome! So now let’s repeat the test with Huge Pages but we will increase the size to 4MB!
Write:
[root@dbVictim ~]# ./shared_memory
Hugepages (1) or regular pages (2): 1
Segment ID 52
Attached at 0x7fbd24a00000
Want to write (1), read (2) or exit (0): 1
How many kb to write: 4096
Want to write (1), read (2) or exit (0):
Read:
[root@dbVictim ~]# ./shared_memory
Hugepages (1) or regular pages (2): 1
Segment ID 52
Attached at 0x7fa3cd200000
Want to write (1), read (2) or exit (0): 2
Read 4194304 bytes
Want to write (1), read (2) or exit (0):
And Rss?
[root@dbVictim ~]# cat /proc/`pidof -s shared_memory`/smaps | grep 42b33125 -A 22
7fa3cd200000-7fa3cdc00000 rw-s 00000000 00:0f 52 /SYSV42b33125 (deleted)
Size: 10240 kB
KernelPageSize: 2048 kB
MMUPageSize: 2048 kB
Rss: 0 kB
Pss: 0 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 0 kB
Private_Dirty: 0 kB
Referenced: 0 kB
Anonymous: 0 kB
LazyFree: 0 kB
AnonHugePages: 0 kB
ShmemPmdMapped: 0 kB
FilePmdMapped: 0 kB
Shared_Hugetlb: 6144 kB
Private_Hugetlb: 0 kB
Swap: 0 kB
SwapPss: 0 kB
Locked: 0 kB
THPeligible: 0
VmFlags: rd wr sh mr mw me ms de ht sd
Nothing! No Rss, no Pss – all clear! 🙂
So what is the conclusion? There was no problem at all! The only problem there was, was a problem with interpreting the statistics 🙂
And why they noticed the problem? Well, it was not the database version issue as you may suspect by now – they started a test database on that server, before the production database instance – and it consumed most of the huge pages, thus forcing production instance to use regular ones which caused a panic because of a high memory consumption by Oracle processes.
So next time when you say to a consultant "nothing changed" think twice – because in this situation thee change was the order of starting 2 instances of Oracle RDBMS on the same server.