So we had a doubtful pleasure of migrating a few databases from Oracle Exadata X3-2 to Oracle Exadata X7-2 Cloud at Customer.
Why doubtful? Well, this a material for a whole different story with a lot of beer – let me just say, that CC gen 1 was a bit rough around the edges 😉
At least we had a lot of interesting cases worth mentioning – and this is a story of one of them.
When we migrated a test database from X3 to X7CC a customer reported, that performance tests ran much worse on the new environment. Well, we were not surprised, to be honest… At least at the start.
Let me show a comparison of 2 AWR reports I analyzed after the first performance test.
Let’s start with compering the time models:
X3

X7-CC

If we compare "SQL Exec Ela (s)", we will notice that on X7-CC the SQL execution time was actually shorter than on X3. But the interesting thing can be noticed in the Standard Deviation – X7-CC has a much higher value of this statistic. This makes me think, that in general everything was better, but there should be at one SQL that lasted much, much longer.
Let’s check wait events for those 2 environments:
X3
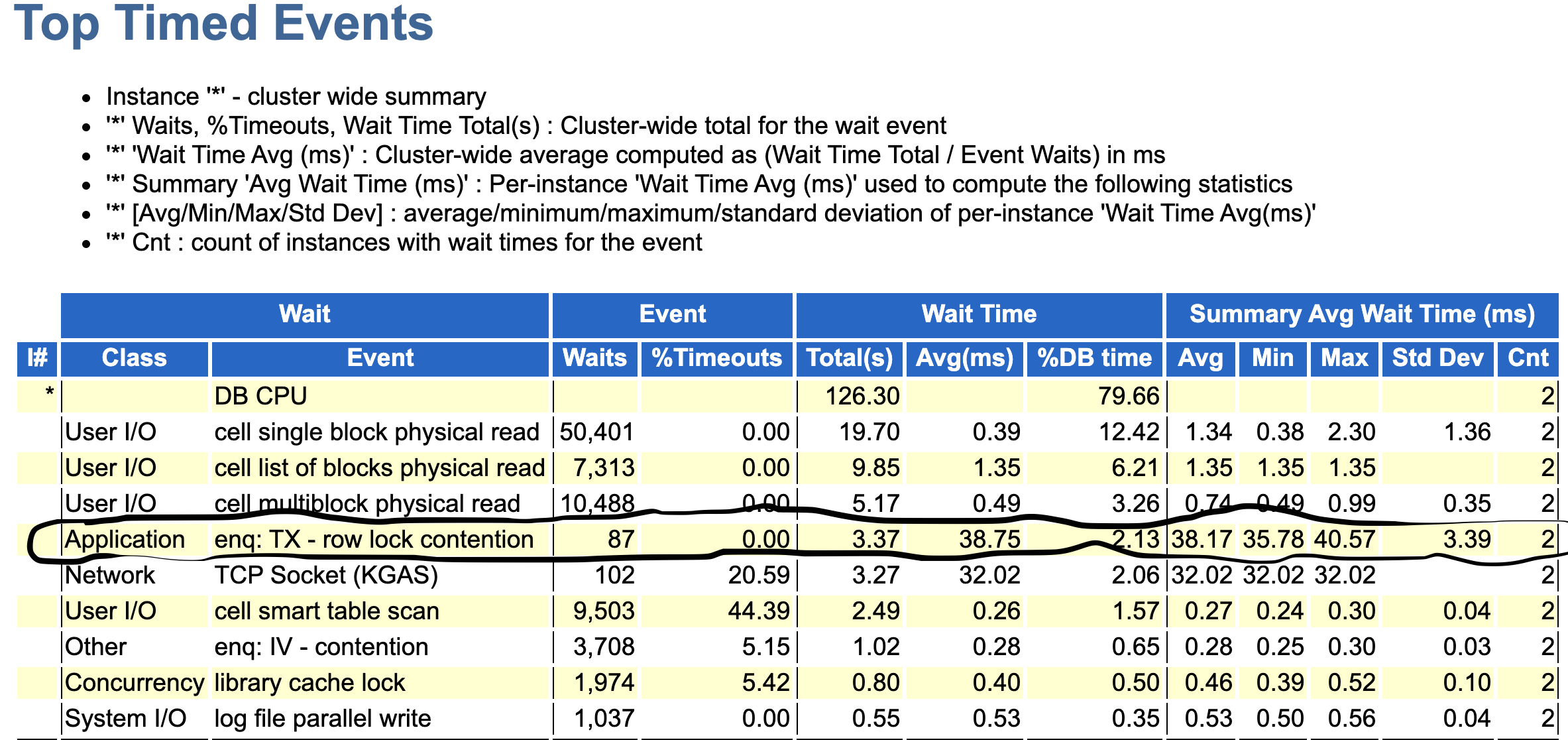
X7-CC
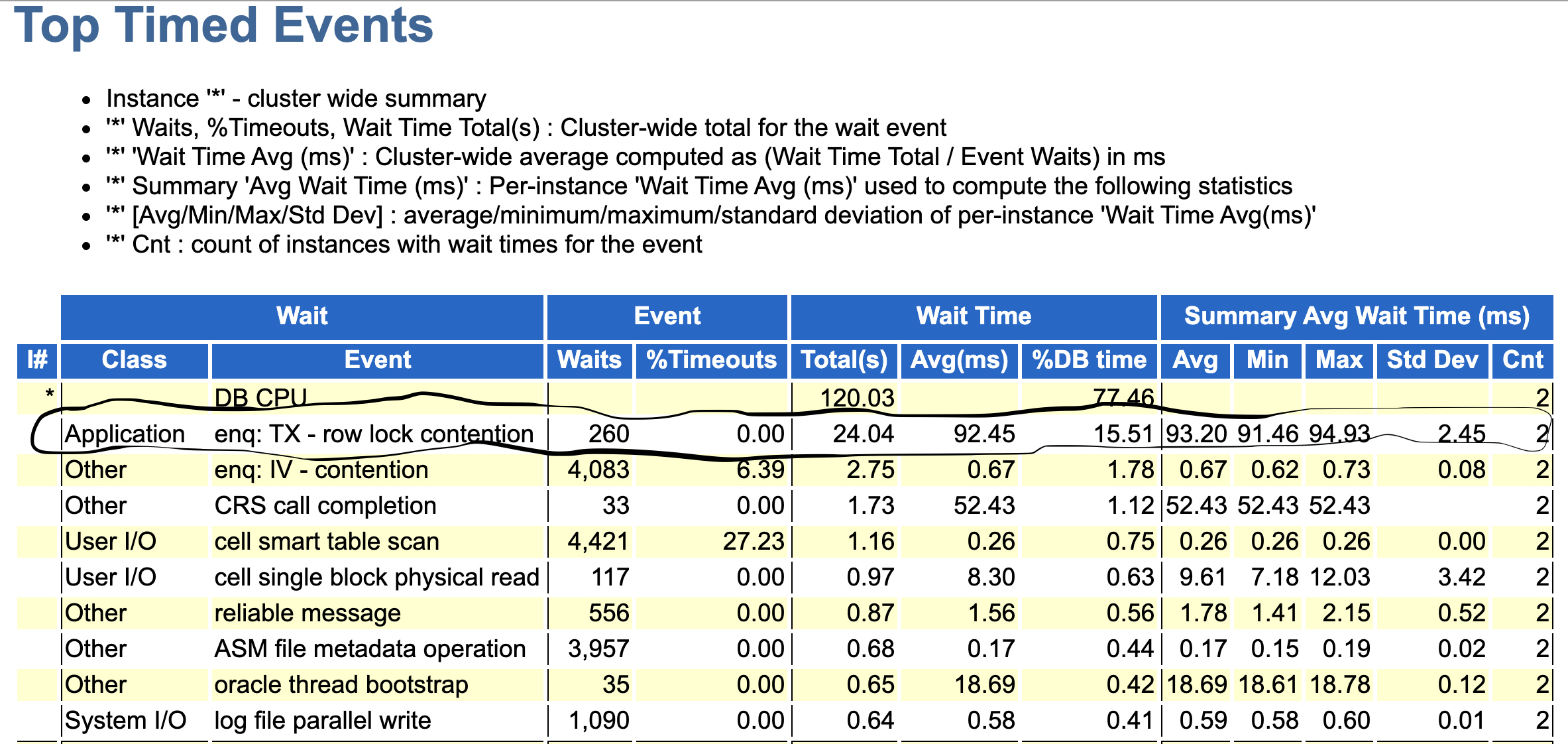
One wait events stand out – "enq: TX – row lock contention". On X7-CC we have waited 7 times longer for this wait event! I know for sure, that those 2 databases were exactly the same because I personally performed a clone with RMAN before the test.
So what is happening? Let’s start with understanding how a row lock actually works.
To explain it, I’ll use my tool RICO2: https://github.com/ora600pl/rico2
Let’s consider a simple update:
SQL> update hr.employees set salary=salary*2; Zaktualizowano wierszy: 107. SQL> alter system checkpoint; Zmieniono system.
The result of this update is some a transaction:
SQL> select xid, status, XIDUSN, XIDSLOT, XIDSQN 2 from v$transaction; XID STATUS XIDUSN XIDSLOT XIDSQN ---------------- ---------------- ---------- ---------- ---------- 08001E00C90C0000 ACTIVE 8 30 3273
As you can see, ID of the transaction (XID) is a combination of 3 fields: XIDUSN, XIDSLOT, XIDSQN.
Now, let’s see how does it look at the block level. This is our row:
rico2 > set dba 10,43547 DBA 0x280aa1b (41986587 10,43547) rico2 > p *kdbr[0] rowdata[7801] @8126 0x2c ------------- flag@8126: 0x2c lock@8127: 0x2 cols@8128: 11 col 0[2] @8129: c202 col 1[6] @8132: 53746576656e col 2[4] @8139: 4b696e67 col 3[5] @8144: 534b494e47 col 4[12] @8150: 3531352e3132332e34353637 col 5[7] @8163: 78670611010101 col 6[7] @8171: 41445f50524553 col 7[3] @8179: c30551 col 8[0] @8183: *NULL* col 9[0] @8184: *NULL* col 10[2] @8185: c15b
The construction of this row in plain hex looks like this:
[oracle@voodoo ~]$ xxd -g 1 -s $((43547*8192+8126)) -l 59 /opt/oracle/oradata/XE/XEPDB1/sysaux01.dbf 15437fbe:2c 02 0b 02 c2 02 06 53 74 65 76 65 6e 04 4b 69 ,......Steven.Ki 15437fce:6e 67 05 53 4b 49 4e 47 0c 35 31 35 2e 31 32 33 ng.SKING.515.123 15437fde:2e 34 35 36 37 07 78 67 06 11 01 01 01 07 41 44 .4567.xg......AD 15437fee:5f 50 52 45 53 03 c3 05 51 ff ff _PRES...Q..
The second byte of the row bytestring (in this case 0x02) is a lock byte. What does it mean? Well, it means, that this byte points to second element in ITL slot in ktbbh structure of the database block.
rico2 > p ktbbh
struct ktbbh, 72 bytes @20
ub1 ktbbhtyp @20 0x1
union ktbbhsid, 4 bytes @24
ub4 ktbbhsg1 @24 0x11eb1 [raw hex: b11e0100 OBJD: 73393]
ub4 ktbbhod1 @24 0x11eb1
struct ktbbhcsc, 8 bytes @28
ub4 kscnbas @28 0x7afe74 [raw hex: 74fe7a00]
ub2 kscnwrp @32 0x8000
sb2 ktbbhict @36 0x2
ub1 ktbbhflg @38 0x32
ub1 ktbbhfsl @39 0x0
ub4 ktbbhfnx @40 0x100aa18 [raw hex: 18aa0001]
struct ktbbhitl[0], 24 bytes @44
struct ktbitxid, 8 bytes @44
ub2 kxidusn @44 0x4 [raw hex: 0400]
ub2 kxidslt @46 0x12 [raw hex: 1200]
ub4 kxidsqn @48 0x1d8 [raw hex: d8010000]
struct ktbituba, 8 bytes @52
ub4 kubadba @52 0x24010a7 [raw hex: a7104002]
ub2 kubaseq @56 0xd8 [raw hex: d800]
ub1 kubarec @58 0x46
ub2 ktbitflg @60 0x8000 [raw hex: 0080]
union _ktbitun, 2 bytes @62
sb2 _ktbitfsc @62 0x8000 [raw hex: 0080]
ub2 _ktbitwrp @62 0x8000 [raw hex: 0080]
ub4 ktbitbas @64 0x167b11 [raw hex: 117b1600]
struct ktbbhitl[1], 24 bytes @68
struct ktbitxid, 8 bytes @68
ub2 kxidusn @68 0x8 [raw hex: 0800]
ub2 kxidslt @70 0x1e [raw hex: 1e00]
ub4 kxidsqn @72 0xcc9 [raw hex: c90c0000]
struct ktbituba, 8 bytes @76
ub4 kubadba @76 0x24007a7 [raw hex: a7074002]
ub2 kubaseq @80 0x355 [raw hex: 5503]
ub1 kubarec @82 0x23
ub2 ktbitflg @84 0x62 [raw hex: 6200]
union _ktbitun, 2 bytes @86
sb2 _ktbitfsc @86 0x0 [raw hex: 0000]
ub2 _ktbitwrp @86 0x0 [raw hex: 0000]
ub4 ktbitbas @88 0x0 [raw hex: 00000000]
Looks familiar? The second slot of ktbbhitl array contains our ktbitxid with 3 fields, that combined will give us our XID.
Now (in simplification), when another transaction is about to modify this row, it checks the row lock flag, goes to appropriate ktbbhitl slot and then checks if this transaction is still active or not. If it is active – we are waiting for "enq: TX – row lock contention".
As you can see, there’s nothing we can do about it from a DBA perspective, since this is purely an APP thing. And this wait event is also in "Application" class.
So if a database is a binary clone, and the test case was generic – why the difference?
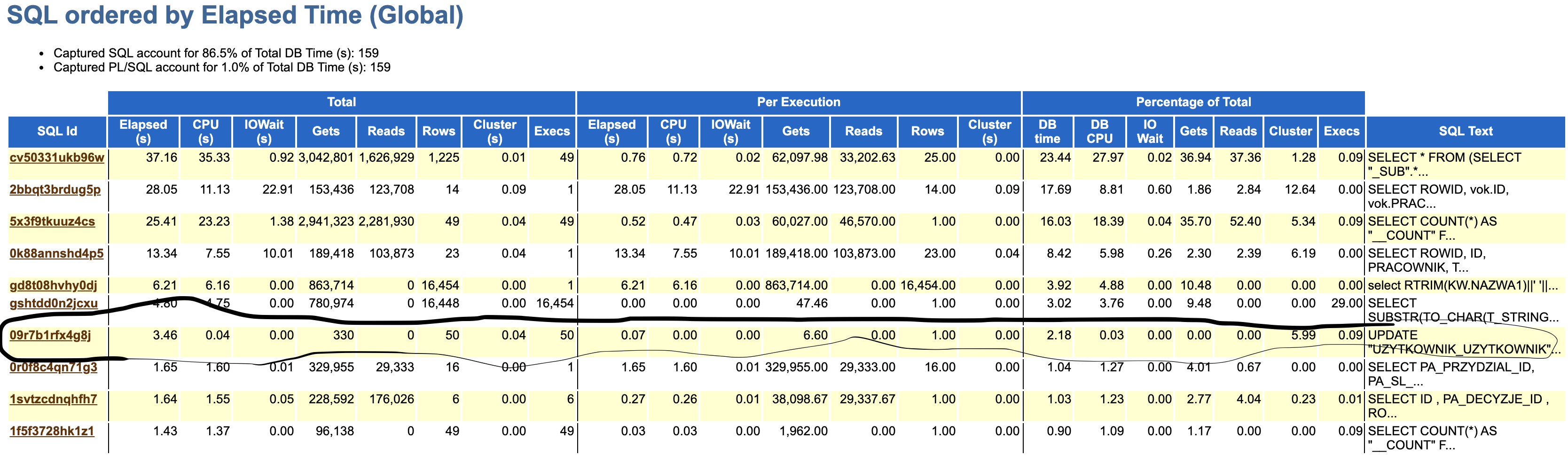
Let’s check actual SQL’s in AWR report:
X3
X7-CC
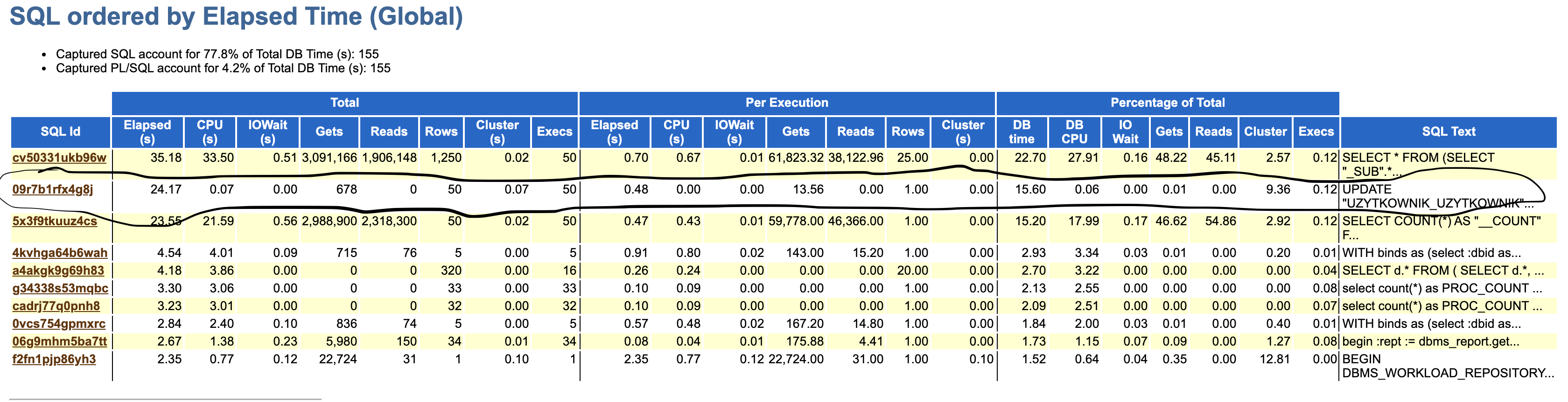
As we expected the main difference is with one special SQL – UPDATE.
UPDATE "UZYTKOWNIK_UZYTKOWNIK" SET "PASSWORD" = :arg0, "LAST_LOGIN" = :arg1, "IS_SUPERUSER" = :arg2, "USERNAME" = :arg3, "FIRST_NAME" = :arg4, "LAST_NAME" = :arg5, "EMAIL" = :arg6, "IS_STAFF" = :arg7, "IS_ACTIVE" = :arg8, "DATE_JOINED" = :arg9, "DATA_UTWORZENIA" = :arg10, "DATA_MODYFIKACJI" = :arg11, "ZDALNY" = :arg12, "TELEFON" = :arg13, "WYDZIAL" = :arg14, "OSTANIA_AKCJA" = :arg15, "ZDJECIE" = :arg16 WHERE "UZYTKOWNIK_UZYTKOWNIK"."ID" = :arg17
The first look at this UPDATE tells us, that it was not executed from PL/SQL, but rather from an APP directly and this already tells us everything we need to know!
This UPDATE was actually executed from Python3 and it looked something like this:
import cx_Oracle, os, datetime
conn_obj = cx_Oracle.connect("hr/hr@192.168.56.18:1521/rokoko")
sql = conn_obj.cursor()
sql.execute("update employees set salary=salary where employee_id=100");
conn_obj.commit()
sql.close()
conn_obj.close()
I mean, that directly after an update, there was commit – so, in theory, this is an immediate and short transaction.
Let’s check how does it look from a network perspective:
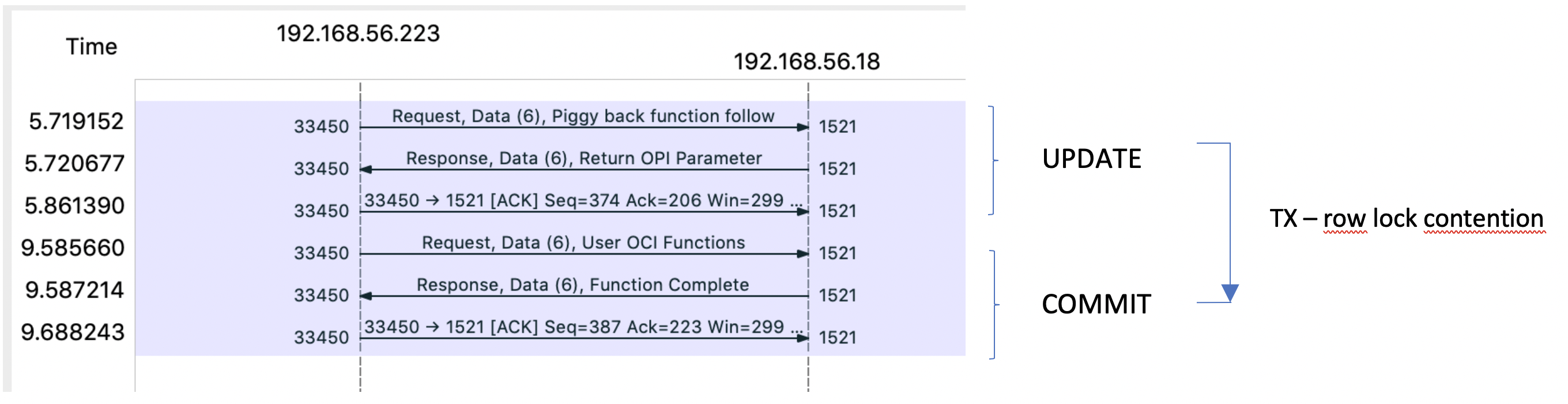
This means, that we need at least 4 packets to begin and end our transaction. The test server and Exadata X3-2 were in the same server room, while the Exadata X7 Cloud at Customer was located around 10km and a few switches and routers away.
Because of that, RTT (packet round trip time) for X3 was max. 49ms, while RTT for X7 was up to 150ms.
Those delays have a tendency to pile up when you use multiple sessions (50 sessions in this case) and cause performance problems.
If the same business logic would be written in PL/SQL – we wouldn’t notice any problem at all!
So what is the conclusion? Design is everything. #SMARTDB philosophy these days (when everyone is forcing you to use cloud) is more important than ever before.
If your application is chatty and is using a lot of packets to solve the same problem – you are not cloud-ready.